[김상현(북미 전문 에디터)] 야구 실력 못지않게 기발하거나 황당한 언사로 팬들의 사랑을 받았던 전설의 야구 선수 요기 베라 (Yogi Berra)는 이런 말을 남겼다. “예측은 어렵다. 특히 미래에 관해서는.” 하나마나 한 말처럼 들리지만, 요즘만큼 이 말이 적절하게 여겨진 때도 달리 없었던 것 같다. 하루가 다르게 데이터가 폭증하는 ‘정보 폭주’의 시대, ‘빅데이터’의 시대에 “예측은 어렵다. 특히 미래에 관해서는.”
빅데이터는 어떤 면에서 동전의 양면이고, 모순이며, 역설이다. 사상 그 유례를 찾아볼 수 없는 어마어마한 양의 데이터를 어떻게 수집, 조합, 분석하느냐에 따라 더없이 정확한 예측을 할 수 있게 해주는 가능성이 그 한 면이라면, 자칫 잘못하면 그 데이터의 숲에서 길을 잃거나 정보의 홍수에 속절없이 떠밀려 헤어날 수 없게 되는 위험성이 그 다른 면이기 때문이다. 그 데이터가 한 개인에 관한 경우라면, 그의 프라이버시가 심각하게 침해되는 위험성도 떠올릴 수 있을 것이다.
빅데이터? 도대체 얼마나 크길래? 아니, 많길래? 이 단순한 질문에 대답하기조차 버거울 만큼 빅데이터의 규모는 ‘빅’하다. 복잡하다. 무엇보다 시시각각 가파른 속도로 늘고 있기 때문에 언제 어느 시점에서 추정했느냐에 따라, 또 어떤 기관이나 기업이 조사했느냐에 따라 그 규모는 다른 양상과 숫자로 나타나기도 한다. 그럼에도 공통점은 어느 수치든 ‘억’ 소리 나게 방대하다는 점이고, 앞으로 더욱 빠르게 늘어날 것이며, 그로 인한 위기 - 위험과 기회 - 도 엄청나리라는 것이다.
빅데이터의 한 단면
(1) 우주의 별보다도 더 많은 디지털 데이터
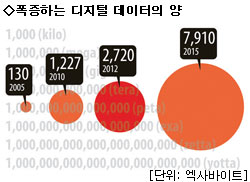
IDC에 따르면 전세계 디지털 데이터의 규모는 2010년에 1천227EB로 늘었고, 올해는 2천720EB에 이를 전망이며, 2015년에는 8천EB에 육박할 것으로 보인다. 이게 도대체 얼마나 큰 규모냐고? 이를 비트로 환산하면, 현재 우주 전체의 별보다도 세 배나 더 많은 숫자에 해당한다. 과연 IDC가 그 보고서의 제목을 ‘디지털 우주’라고 표현할 만하지 않은가.
(2) 2012년의 디지털 데이터 분석
데이터의 양적 팽창을 주도하는 것은 비디오다. 이런 사실은 당신의 노트북이나 데스크톱의 저장 공간을 무엇이 가장 많이 차지하고 있는지 들여다봐도 금방 드러난다. 비디오다. 유튜브의 자료에 따르면, 유튜브를 통해 매일 시청되는 비디오 수는 30억 편에 이른다. 개인이 올리는 비디오를 정식 영화 길이로 환산하면 매주 24만 개의 영화가 만들어지는 꼴이라고 한다.
단 한 달 동안 유튜브로 올라가는 비디오 편수가, 미국의 3대 메이저 영화사가 지난 60년간 만든 양보다 더 많다는 자료도 들어 있다.
2012년 약 2천720EB에 이를 것으로 보이는 전체 디지털 데이터 중에서도 비디오의 비중이 단연 압도적이다. 전체의 92%에 해당하는 2천500EB (혹은 250만 페타바이트 (PB))가 비디오를 포함한 이미지로 채워질 전망이다. 음성과 기타 데이터는 전체 그림으로 보면 상대적으로 미미하다.
한편 하드웨어적인 면을 보면 PC가 아닌 다른 네트워크 기기들, 예컨대 스마트폰이나 태블릿 같은 개인용 디지털 기기의 확대가 데이터의 양적 팽창을 부추긴 것으로 보인다. 시스코는 2015년쯤에는 무선 기기를 이용한 인터넷 트래픽이 유선 기기의 인터넷 접속량을 넘어설 것이라고 전망했다.

(3) 빅데이터의 최대 생산자는 개인
140자 이하의 텍스트로 소통(트윗)하는 ‘마이크로 블로깅’ 사이트 트위터(Twitter)는 빅데이터의 추이를 표나게 보여주는 한 사례다. 인간이 상상할 수 있는 거의 모든 소재와 주제가 오가는 트위터야말로 개별 이용자의 데이터 생산량이 얼마나 막대한지를 생생하게 보여주는 ‘라이브 무대’이다. 지난 6월말 현재, 하루 소통되는 트윗 수만 2억개를 넘었다. 1년 전인 2010년의 하루 6천500만 트윗보다 3배 이상 늘어난 수치다. 2009년의 하루 트윗 수는 200만여 개였다.
페이스북은 또 어떤가. 이용자만 8억명을 넘긴 이 소셜 네트워킹 사이트를 통해 매일 2억5천만장의 사진이 올라간다. 이용자 한 사람당 평균 80개의 커뮤니티 페이지나 그룹, 이벤트 등에 연결되어 있으며, 3억5천만명 이상이 모바일 기기를 통해 페이스북에 접속하고 있다.
트위터와 페이스북의 사례는 빅데이터의 출처가 더 이상 대기업이나 정부 기관만이 아니라는 점을 시사한다. 아니, 그 이상이다. EMC/IDC 보고서에 따르면, 시시각각 생성되는 디지털 데이터의 75%가 기업이나 기관이 아닌 개인이다!
(4) 디지털 세계의 역설: 비용은 줄고, 투자는 늘고
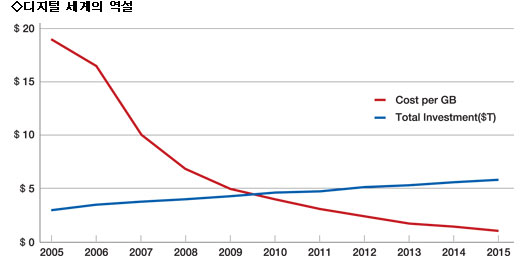
‘빅데이터 현상’을 부추기는 주요 변수 중 하나는 ‘디지털의 역설’이라는 말로 설명할 수 있다. 저장매체의 비용은 가파르게 줄어드는 반면, 저장매체를 포함한 IT 분야에 대한 투자 규모는, 비록 데이터 자체의 폭발적 증가세와는 견줄 바가 못되지만, 꾸준히 늘고 있는 것이다. IDC의 자료에 따르면 2005년 1GB당 19달러 대에 달했던 저장매체의 비용은 2011년 3달러 미만 수준으로 떨어졌다. 2015년에는 1달러도 안되는 66센트 수준까지 내려갈 것이라는 전망이다.
저장매체의 비용이 이처럼 급속도로 낮아지지 않았다면 지금의 ‘빅데이터’ 중 상당 부분은 다음 데이터에 공간을 내주기 위해 단기간에 삭제되거나 폐기됐어야 할 것이고, 따라서 데이터의 오랜 축적에 따른 심층 분석도 한층 더 어려웠을 것이다. 한편 저장매체와 관련 시스템에 대한 투자 규모는 2005년 2조7천억달러 수준에서 1015년 5조2천억달러 (약 5천700조원)으로 꾸준히 증가할 것으로 보인다.
폭주하는 데이터의 양을 감당하기 위해 저장매체 또한 큰 폭으로 증가하리라는 것은 불을 보듯 뻔하다. 문제는 그 증가율이 불균형을 보일 것이라는 점이다. 향후 10년 동안, 서버의 숫자는 매년 10%의 성장률을 보일 전망인 데 견주어 기업형 데이터센터가 관리할 정보의 양은 연 50%씩 늘어나고, 파일의 숫자는 적어도 75%의 증가율을 보일 것이라는 점이다. 한편 이 분야 IT 전문가의 숫자는 채 1.5%도 안되는 수준으로 더디게 늘어날 전망이다. 그 결과 이 모든 디지털 데이터를 제대로 관리, 분석, 경영할 수 있는 기술과 경험, 자원에 대한 수요와 공급 간에 심각한 불균형이 초래될 것으로 보인다. 그리고 클라우드 컴퓨팅은 이 불균형을 다소나마 해소해 줄 수 있는 유력한 대안으로 떠오를 것이다.
요타바이트의 세계
아직도 많은 이들은 기가바이트나 테라바이트 단위에도 고개를 갸우뚱하기 일쑤다. 하지만 이제는 페타바이트, 엑사바이트, 제타바이트를 넘어 요타바이트까지, 혹은 그 이상으로 더 나가야 할 처지다. 제타바이트는 1조GB이고, 요타바이트는 1천조GB이다. 지난해의 디지털 데이터 규모가 1.2제타바이트였고, 올해가 1.8제타바이트, 혹은 1천800엑사바이트로 추산되니 그럴 만도 하다. 포레스터 리서치, 가트너 리서치, IDC 등 내로라 하는 IT 시장 조사 기관들이 하나같이 내년의 주요 흐름 중 하나로 ‘빅데이터’와 그를 둘러싼 분석과 해석학(analytics)의 붐을 꼽는 것도 마찬가지 맥락이다.
수많은 기업, 기관들이 공급망 관리로부터 고객 관계 관리에 이르기까지 IT 시스템을 통해 끊임없이 수집하고 축적해 온 막대한 디지털 데이터를, 사상 유례없이 강력해진 컴퓨터 연산 능력과 값싼 저장매체, 첨단 해석 기법을 활용해 최적화할 것이라는 전망이다. 여기에 새로운 유형의 데이터베이스인 ‘하둡(Hadoop)’이 대량의 데이터 흐름을 실시간으로 걸러줄 수 있을 것이다. 이 데이터에는 단지 정해진 규격 안의 숫자만이 아니라, 흔히 ‘비구조화 데이터(unstructured data)’ 로 분류되는 이메일이나 워드프로세서 등의 일반 텍스트도 포함된다.
전망 - 기회
영국의 경제 전문지 ‘이코노미스트’는 새해를 전망하는 별책 ‘2012년의 세계’에서, 감지기(sensor)가 속도로부터 냄새에 이르는 모든 것을 측정하고 기록하는 세계를 그렸다. 스마트폰의 ‘앱’들은 막대한 양의 ‘데이터 배기가스(data exhaust)’를 생산할 것이다. 이것은 스마트폰 이용자들이 가령 스키를 타다가 넘어지거나 떨어졌을 경우, 동작 감지기 덕택에 다른 사람들이 그 사실을 알게 되는 상황을 비유한 것이다. 또 트위터와 페이스북으로 대표되는 소셜 미디어가 빅데이터의 성장에 한몫 할 것으로 내다봤다.
기업들은 방대한 데이터로부터 어떤 식으로든 최대 가치를 뽑아낼 수 있을 것으로 기대한다. 씽크탱크 중 하나인 ‘매킨지 글로벌 인스티튜트’는 의료 데이터를 제대로 분석하는 것만으로도 미국에서만 3천억달러 규모의 비용 절감 효과를 거둘 수 있을 것으로 추정했다. 이코노미스트의 보도에 따르면 영국의 국립의료임상연구원(National Institute for Health and Clinical Excellence)은 이미 대규모 데이터를 가지고 신약과 기존 고가 치료법의 비용과 혜택을 연구하고 있다.
마케팅 회사, 광고 회사들은 차고 넘치는 인터넷 이용자들의 행태 데이터를 통해 사상 유례없이 정확한 수요 예측이 가능해질 것으로 본다. 실시간 위치정보 분석을 통해 이용자가 있는 장소와 환경에 최적화 된 마케팅도 가능하다.
빅데이터에 특화된 벤처기업, 특히 소셜미디어와 연계한 창업도 일대 붐을 이룰 것으로 보인다고 이코노미스트는 전망했다. 예컨대 ‘렉살리틱스(Lexalytics)’는 트위터와 페이스북, 기타 소셜 네트워킹 사이트들의 데이터를 수집해 이용자들의 감성을 분석하는 기업이다. ‘클라우트(Klout)’라는 회사는 소셜미디어 이용자들의 영향력을 측정한다. 이미 몇몇 회사들은 높은 클라우트 점수를 가진 이용자를 우대한다.
그런가 하면 ‘디사이드(Decide.com)’라는 곳은 수백 개의 온라인 상점들로부터 10만 개 이상의 전자제품 가격을 수집하는 한편, 전자제품과 관련된 블로그, 소문 등을 모아 분석해서, 가격이 언제 올라가거나 내려갈지 예측한다. 그를 위해 이 회사가 매일 새로 더하는 데이터는 25GB에 이른다. 또 뉴욕타임스에 소개된 ‘기록된 미래(Recorded Future)’ 라는 회사는 시간당 10만개의 웹 페이지를 훑고, 미국 증권거래위원회 자료로부터 트위터의 트윗 내용에 이르기까지 5만여 소스를 스캐닝 한다. 그렇게 ‘기록된’ 자료들을 통해 다종다양한 미래를 예측한다는 개념이다.
전망- 위험
그러나 빅데이터가 여러 낙관적 전망대로 활용되기 위해서는 여러 장벽을 넘어야 한다. 그 중 하나는 데이터 분석 툴이 아직 충분히 뛰어나지 못하다는 점이고, 다른 하나는 데이터를 분석하고 해석할 수 있는 역량의 전문가가 턱없이 부족하다는 점이다. 매킨지에 따르면 2018년쯤 그러한 ‘인력의 격차’가 14만~19만 명에 이를 전망이다.
또 하나는 프라이버시 문제다. 1년 365일, 그것도 24시간 개개인의 일거수일투족이 녹음되거나 녹화되고, 기록되며, 그의 온라인 활동, 스마트폰 이용 행태가 시시콜콜한 데이터로 기업들에 저장되어 조합되고 분석된다. 내 모든 말과 행동이 마케팅의 재료로 활용된다. 소셜미디어에 내가 직접 올린 글이나 사진, 비디오뿐 아니라, 남이 나에 대해 한 말, 글, 멀티미디어가 또한 나에 대한 ‘영구 기록’으로 남아 수정되고 업데이트 된다. 과연 빅데이터의 시대에, 나의 프라이버시는 어떻게 확보할 수 있을까? 빅데이터의 빛과 그늘을 동시에 들여다보고 고려하는, 균형 감각이 절실히 요청된다.
/김상현(북미 전문 에디터) kevin.sh.kim@gmail.com


--comment--
첫 번째 댓글을 작성해 보세요.
댓글 바로가기